Using string concatenation vs. join for building long strings
Consider the following two simple scripts:
#!/usr/bin/python3
import sys
import time
n = int(sys.argv[1])
t0 = time.clock_gettime(time.CLOCK_MONOTONIC)
s = ""
for i in range(n):
s += str(i)
t1 = time.clock_gettime(time.CLOCK_MONOTONIC)
print(n, t1-t0, n / (t1 - t0))
#!/usr/bin/python3
import sys
import time
n = int(sys.argv[1])
tick_size = 1000000
t0 = time.clock_gettime(time.CLOCK_MONOTONIC)
elems = []
for i in range(n):
elems.append(str(i))
s = "".join(elems)
t1 = time.clock_gettime(time.CLOCK_MONOTONIC)
print(n, t1 - t0, n / (t1 - t0))
Both concatenate the (decimal) numbers from 0 to n-1 to simulate serializing the output of some process (maybe computing lots of values, maybe reading a large dataset from a database).
The first one just appends to the result string as it goes along. The second one builds a temporary list and then uses join to turn this into a string in one go.
These scripts were run with varying n on a 32 bit Linux (which caps the process size at about 3GB) until a MemoryError occured.
The graph compares the performance between the scripts (run time in seconds, lower is better):
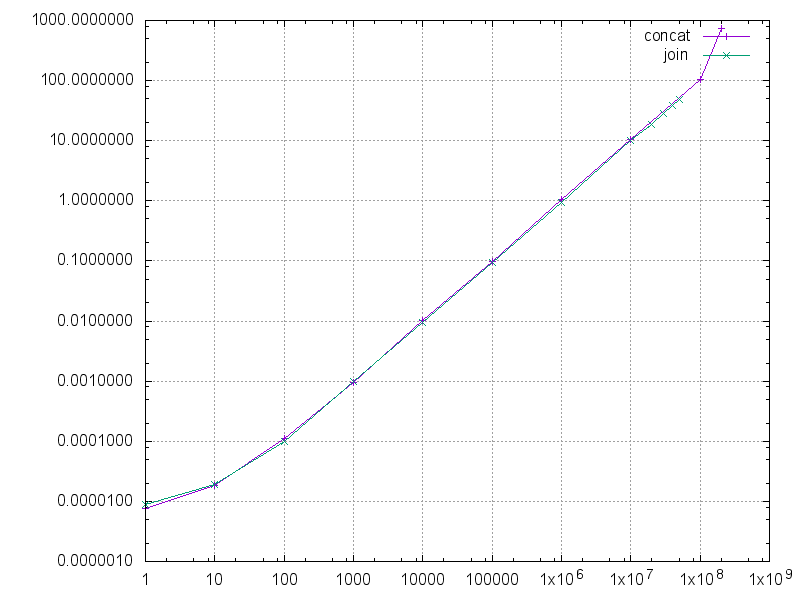
For each n the performance is almost exactly the same (join seems to be usually a tiny bit faster), but the line for join ends at 60×10⁶, while the line for concat continues until 200×10⁶. So concat can process more than 3 times as many numbers at the same memory consumption.
(I believe that the drastically longer run timer for the 200×10⁶test is because that caused other processes to be swapped out — the join tests came after and had enought free RAM. I probably should rerun all test in random order multiple times to remove such artifacts.)