Blob Benchmarks
Introduction
This simple benchmark fills a table with binary objects (more specifically, bytea values in PostgreSQL) of random size. The sizes of the objects follow a log normal distribution to simulate “natural” file sizes. After the table has reached the target size, random rows are read from the table and the size of the blob and the time to read it are correlated.
Results
These results where obtained with PostgreSQL 9.5 on an Intel(R) Core(TM) i5-6400 CPU @ 2.70GHz with 32 GB RAM runnding Debian 8. The database was on a single Samsung 850Evo SSD.
The graphs are for a total table size of 1GB, 10GB and 100GB respectively. The maximum size of a single blob was capped at 100 MB in all cases.
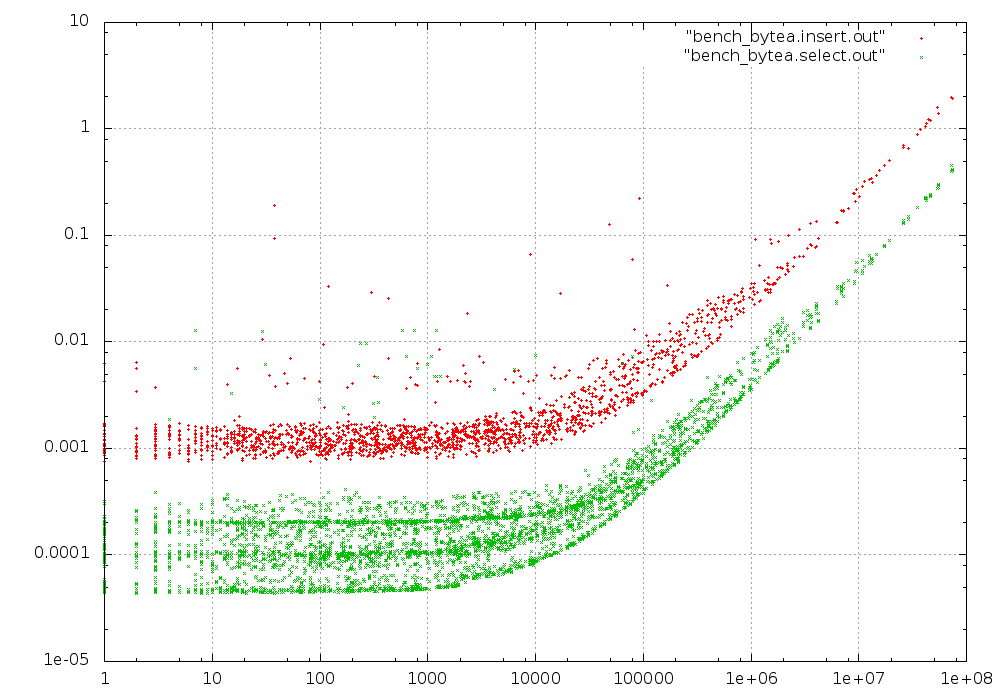
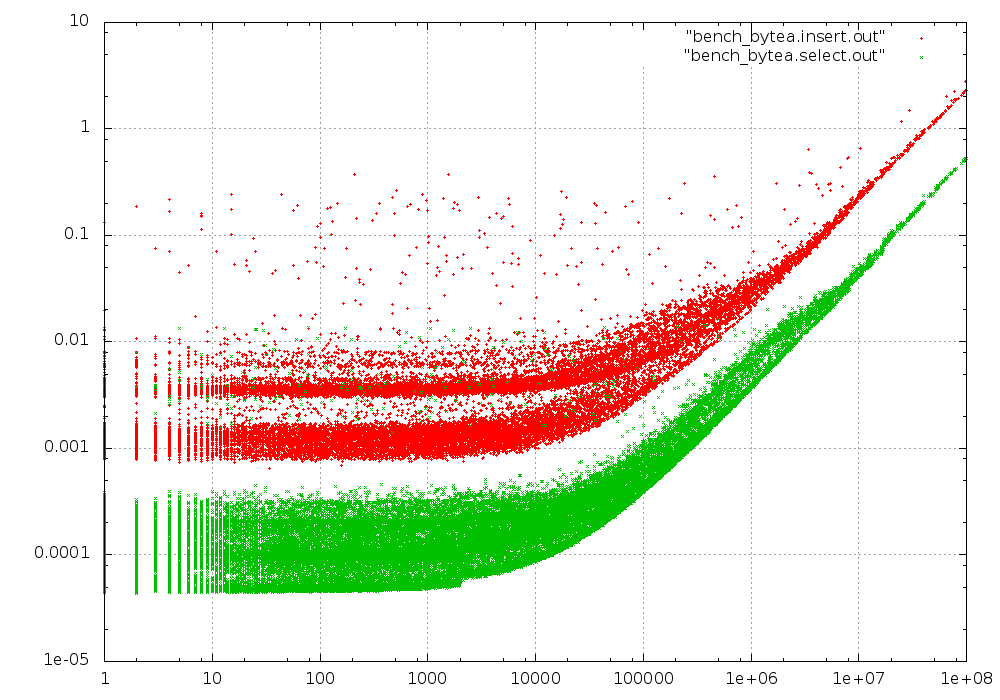
At 10 GB (still small enough to fit into RAM), we start to see a second, slower peak for the insert times. We also see a discontinuity for the fastest select times at 2 kB - The size where PostgreSQL starts moving contents to TOAST storage.
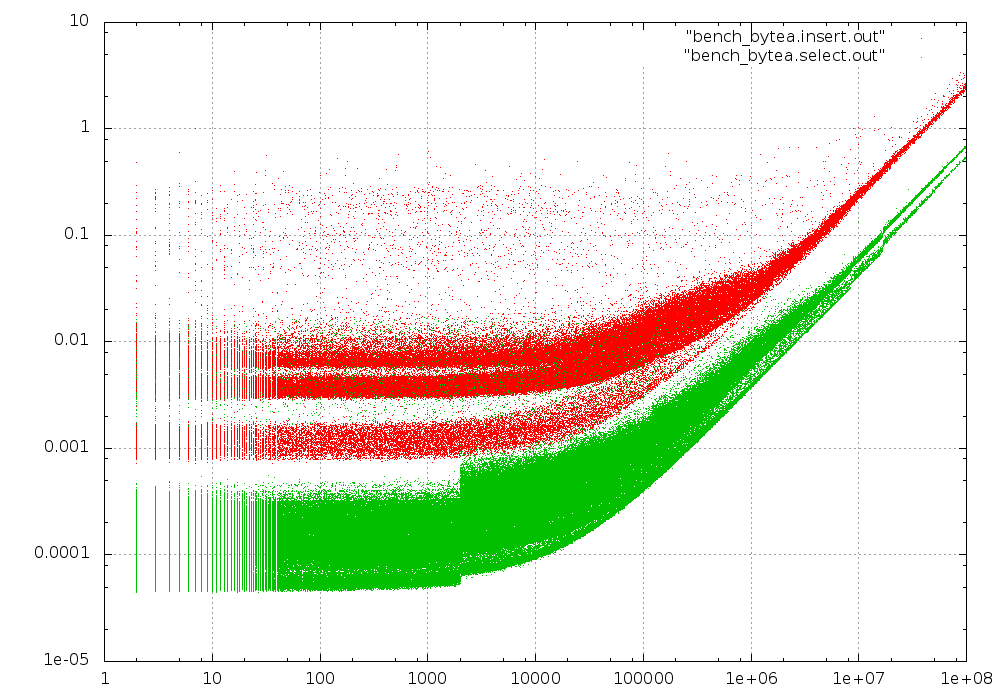
At 100 GB, most inserts for small blobs are now at the slower peak (which itself has bifurcated). The discontinuity at 2kB is much more pronounced and now not only affects the fastest select times, but also the slowest.
Curiously, the speed for large blobs (both insert and select) seems to be mostly independent of the database size. It doesn't seem to make much difference whether data can be retrieved from the disk cache or from SSD.
The script
bench_bytea (Python 3)